ნებისმიერი კორპუსის შექმნა, უპირველეს ყოვლისა, ტექნოლოგიური პრობლემების გადაჭრით იწყება. ტექნოლოგიური პრობლემების ხასიათი და სირთულე თავად რესურსების შინაარსობრივ და ფორმობრივ პარამეტრებზე არის დამოკიდებული. ამ თავში ჩვენ განვიხილავთ იმ ტექნოლოგიურ პრობლემებსა და საკითხებს, რომელთა გადაჭრაც ქართული ენის ეროვნული კორპუსის შექმნის დროს მოგვიხდა.
ქართული ენის ეროვნული კორპუსი შეიქმნა ქართული ენისათვის უკვე არსებული რამდენიმე კორპუსის მასალას – TITUS, ARMAZI, GEKKO, GDC, Opentext, Lib.de – ბაზაზე, რომლებიც ერთმანეთისაგან განსხვავდებიან ისეთი არსებითი მახასიათებლების მიხედვით, როგორიცაა კორპუსის სტრუქტურა, ლინგვისტური ანოტაცია, მეტამონაცემები, სამომხმარებლო ინტერფეისი და ა.შ. ქართული ენის ეროვნულ კორპუსში მათი გაერთიანება აუცილებლობით მოითხოვდა, ერთი მხრივ, საერთო ტექნოლოგიური ჩარჩოს კონცეპტუალიზაციას და, მეორე მხრივ, სხვადასხვა კორპუსების რესურსების ტექნოლოგიური თვალსაზრისით გაერთმნიშვნელიანებას.
1. კოდირების საკითხისათვის
ქართული ენის ეროვნული კორპუსის ტექნოლოგიური ჩარჩოს კონცეპტუალიზაცია დაიწყო კოდირების საკითხით. კოდირება (character encoding) არის ლინგვისტური ტექსტის გადაყვანა კომპიუტერული მახსოვრობისათვის გასაგებ ნიშნებში – ბიტებში. კოდირების პირველი, ე. წ. 8-ბიტიანი კოდირების საერთაშორისო სტანდარტი (ISO-8859) სულ მალე 16-ბიტიანმა კოდირების სტანდარტმა შეცვალა, რომელიც სტანდარტების საერთაშორისო კონსორციუმმა უნიკოდმა (UNICODE) 1991 წელს გამოაქვეყნა. ეს გახლავთ მანქანურად წაკითხვადი ტექსტის კოდირებისა და დეკოდირების სტანდარტული სისტემა, რომელიც საერთაშორისო სტანდარტის ISO-10646-ის ნაწილს წარმოადგენს და კოდირების 16-ბიტიან სისტემას იყენებს. კოდირების ახალმა სტანდარტმა შესაძლებელი გახადა ეროვნული ანბანების საყოველთაო სტანდარტიზაცია, მათ შორის, ჩინური იეროგლიფებისაც.
ზოგადი ინფორმაცია UNICODE-ის შესახებ შეგიძლიათ იხილოთ მისამართზე: http://www.unicode.org, ხოლო UNICODE 9-ის ფარგლებში შემუშავებული კოდები http://www.unicode.org/charts/.
დღეისათვის ქართული ანბანის სამივე სახე არის უნიკოდში ასახული: ასომთავრული, ნუსხა-ხუცური და მხედრული:
• მხედრული: U+10D0 – U+10F5
• ასომთავრული: U+10A0 – U+10C5
• http://www.unicode.org/charts/PDF/U10A0.pdf
• ნუსხური: U+2D00 – U+2D25
• http://www.unicode.org/charts/PDF/U2D00.pdf
ქართული ანბანის ნაირსახეობების სტანდარტიზაციაში განსაკუთრებული წვლილი მიუძღვით გერმანელ ქართველოლოგს იოსტ გიპერტსა და ირაკლი ღარიბაშვილს. ის ფაქტი, რომ დღეს უნიკოდის საერთაშორისო სტანდარტების მასალებში ქართული ანბანის სამივე გრაფიკული ვარიანტია ასახული, სწორედ მათი დამსახურებაა.
2. კოდირების სპეციალური პრობლემები ქართული ენის ეროვნულ კორპუსში: ინიციალების, ქარაგმების, ფერების, ზომის კოდირება
კოდირების დროს ერთ-ერთ მნიშვნელოვან ასპექტს წარმოადგენს გრაფემების „ნორმალიზაციის“ საკითხი. ტექსტების კოდირების ნორმალიზაცია ჯერ კიდევ TITUS-ის ფარგლებში განხორციელდა ქართული ენის რესურსებისათვის:

როგორც ხედავთ, ტექსტის დიგიტალიზაციის დროს დაცულია დედნის სპეციფიკური ნიშნები: ასომთავრულით შესრულებული ტექსტები კორპუსში ასახულია ასომთავრულით, ნუსხურით შესრულებული – ნუსხურით. გარდა ამისა, ორიგინალის ტექსტი გადმოტანილია როგორც დედნის, ისე მხედრული ანბანით. დიგრაფემები, რომელიც ასომთავრულისთვის არის დამახასიათებელი (უ-ს გადმოცემა Ⴍ -ს და Ⴣ – ს კომბინაციით), მხედრულით გადმოცემის დროსაც ინარჩუნებს ფონემის დიგრაფემული გადმოცემის პრინციპს. მაგ.:
• ასომთავრული → მხედრული
• ႱႭჃႪႬႤႪႤႡႨ, ႣႠ ႱႾႭჃႠႬႨ
• სოჳლნელები, და სხოჳანი
გრაფემების ნორმალიზაციის პრინციპი ასევე დაცულია ნუსხურით შესრულებული ტექსტების დიგიტალიზაციის დროს: ნუსხურით გადმოცემული ტექსტები მხედრულითაცაა გადმოტანილი:
• ნუსხური → მხედრული
• ⴃⴀ ⴂⴣⴐⴂⴣⴌⴘⴄⴋⴍⴑⴈⴊⴈ ⴈⴞⴀⴐⴄⴁⴑ ⴆⴄⴚⴀⴑ:
• და გჳრგჳნ-შემოსილი იხარებს ზეცას.
ასევე დაცულია საზედაო ასოების გადმოცემის სიზუსტე როგორც ასომთავრულ, ისე შერეულ (ასომთავრულით და ნუსხურით შესრულებული) ტექსტებში.
• ႣႠ ႫႭႾႠႵႭჃႬႣႠ → Ⴃა მოხაქოჳნდა
• Ⴘⴄⴑⴞⴋⴈⴇⴀ ⴑⴓⴊⴈⴄⴐⴈⴇⴀ → Ⴘესხმითა სულიერითა

განსაკუთრებულ პრობლემას კოდირების პროცესში ქმნის ქარაგმების საკითხი. დაქარაგმების პრინციპები ქართული ენის უძველეს ძეგლებში არც ცალსახაა და არც ერთგვაროვანი. ტექსტების ციფრულ ვერსიებში ქარაგმები გახსნილია და საგანგებო ნიშნებითაა მარკირებული:


ქართულ ხელნაწერებში დაქარაგმების პრინციპების შესწავლამ გვიჩვენა, რომ ხელნაწერები დაქარაგმების თვალსაზრისით არსებით განსხვავებას გვიჩვენებენ:
მაგალითად, სიტყვა წინაწარმეტყველებდა, როგორც ეს თანდართული მასალიდანაც ჩანს, სხვადასხვა ფორმით არის დაქარაგმებული ხელნაწერებში.
პრობლემურია აგრეთვე სასვენი ნიშნებისა და ასოების რიცხვითი მნიშვნელობებით გამოყენების შემთხვევების კოდირება კორპუსში, ვინაიდან აღნიშნული ნიშნები ჯერჯერობით არ არის ასახული უნიკოდში.

ქართული ენის ეროვნულ კორპუსში ასევე გასათვალისწინებელია ასოების ფერებისა და ზომების კოდირების საკითხი ისეთი ტექსტებისათვის, როგორიცაა მაგ., ქუთაისის მუზეუმში დაცული ქვემოთ წარმოდგენილი ხელნაწერი:
|
|
 |

როგორც ზემოთ მოყვანილი პრობლემის დახასიათებიდან ჩანს, ტექსტების კორპუსში ადეკვატური წარმოდგენა უკავშირდება არა მარტო ასოების კოდირების საკითხს (character encoding), არამედ ტექსტის მარკირების საგანგებო აღნიშვნის მანქანურ შესაძლებლობებსაც (text markup).
3. ნორმალიზაციის თანამედროვე მიდგომები
ტრადიციული ლინგვისტიკა კარგად იცნობს ტექსტის კრიტიკული რედაქციის ფენომენს. რომელიმე ძეგლის გამოცემის შემთხვევაში ერთმანეთს უდარდება სხვადასხვა რედაქციები და იქმნება ერთი, კრიტიკული რედაქცია.
კორპუსში ტექსტების კოდირების სიზუსტის აღსაწერად ანოტაციის ორი დონე გამოიყენება:
• დიპლომატიური დონე (ნათქვამის, ნაბეჭდი თუ ხელნაწერი ტექსტის ზუსტი ეკვივალენტი, incl. ორთოგრაფიული და გრამატიკული შეცდომები და ა.შ.)
• ნორმალიზებული (ორთოგრაფიისა და გრამატიკის მიხედვით გადამუშავებული – “კრიტიკული გამოცემები”, რომელიც ისტორიული ეტაპებისდა შესაბამისად არის გამართული)
ანუ, ტექსტების ელექტრონული ვერსიების შემთხვევაში ერთმანეთისაგან განასხვავებენ დედნის ზუსტ, ე.წ. დიპლომატიურ ვერსიას და ნორმალიზებულ, ანუ კრიტიკულ ვერსიას.
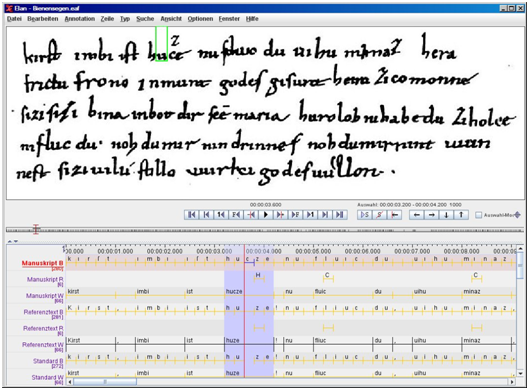
დიპლომატიური ვერსია წარმოადგენს ხელნაწერის ზუსტ ასლს, რომელშიც უპირობოდაა შესული ყველა გრაფემა, ყველა დამატება და შესწორება. კრიტიკულ ვერსიაში კი მეცნიერის (ან მეცნიერთა ჯგუფის) მიერ ხდება ტექსტის ნორმალიზაცია. ელექტრონული ტექსტები ანოტირებულ კორპუსებში მოიცავენ მრავალდონიანი ანოტაციის სისტემას, რომელშიც სხვა მახასიათებელთა გვერდით ტექსტის ნორმალიზებული ვერსიაც არის წარმოდგენილი (ორთოგრაფიული ნორმალიზება).
4. ვერიფიკაციის საკითხი
ელექტრონული ტექსტის ნორმალიზაციისათვის არსებითი მნიშვნელობა აქვს ვერიფიკაციის საკითხს. იმ კორპუსებისათვის, რომლებიც ხელნაწერი ძეგლების ელექტრონულ ვერსიებს მოიცავენ, ვერიფიკაციის ყველაზე დახვეწილი ფორმა არის შესაბამისი ფოტოპირების დართვა.
TITUS-ში განთავსებული ქართული ხელნაწერების უმრავლესობა ვერიფიცირებადია – კოდირების საერთაშორისო სტანდარტის მიხედვით კონვერტირებულ ელექტრონულ ტექსტს თან ახლავს ხელნაწერის შესაბამისი გვერდის ფოტოასლი, რომელიც საშუალებას გვაძლევს კორპუსში ჩართული ლინგვისტური ტექსტი შევუდაროთ ორიგინალს და დავრწმუნდეთ მის ადეკვატურობაში, ან თავად მოვახდინოთ ტექსტში გაუშიფრავი ადგილების გაშიფვრა.
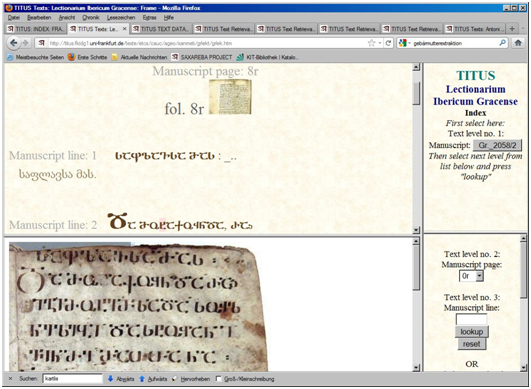
ვერიფიკაციის ამ ფორმას ის მნიშვნელობაც აქვს, რომ იგი საშუალებას აძლევს მეცნიერს სხვადასხვა ქვეყნებში გაბნეულ ხელნაწერებზე სახლიდან გაუსვლელად იმუშაოს.
5. პალიმფსესტების დიგიტალიზაცია
ხელნაწერი ძეგლების ვერიფიკაცია ხშირად პალიმფსესტების დიგიტალურ დამუშავებასთან არის დაკავშირებული. ხელნაწერთა ულტრაიისფერი და ინფრაწითელი ფოტოებით კვლევა მეცნიერების განვლილი ეტაპია. თანამედროვე მეცნიერება დღეს გაცილებით უფრო კომპლექსურ ტექნოლოგიებსა და კვლევის მეთოდებს იყენებს, ვიდრე ეს ფოტომასალების დამუშავებაა. განსაკუთრებით ეფექტური აღმოჩნდა ქართული ხელნაწერების კვლევის დროს მულტისპექტრალური აპარატის MUSIS-ის გამოყენება.
21 საუკუნეში შექმნილი ხელნაწერთა დამუშავების ეს ტექნოლოგიური სიახლე საშუალებას იძლევა ხელნაწერი, მასზე შესრულებული საწერი საღებავების სხვადასხვა დონეების გათვალისწინებით, განსხვავებულ დონეებად გადავიღოთ და დავაცალცალკევოთ. ზედა ფენის ნაწერის “გაფერმკრთალება” გაცილებით “ხილულს” ხდის ძველ, ქვედა ფენას და აადვილებს ხელნაწერის ტექსტის გაშიფვრას.
 |
 |
MUSIS-ის აპარატის გამოყენებით გაიშიფრა სინას მთის ქართული და ალბანური ხელნაწერები და ვენის პალიმფსესტები.