კორპუსის სტრუქტურას შეადგენს სამი არსებითი კომპონენტი: პირველადი მონაცემი, მეტამონაცემი და კორპუსმენეჯერი. განვიხილოთ თითოეული ცალ-ცალკე.
11. სტრუქტურირებული ტექსტი
კორპუსის უმცირეს შინაარსობრივ საბაზისო კომპონენტს წარმოადგენს პირველადი მონაცემი – კოჰერენტული ტექსტი. კორპუსის ეს უმთავრესი კომპონენტი აუცილებლად უნდა იყოს სტრუქტურირებული და ზუსტად უნდა ასახავდეს დედნის სტრუქტურას. განვიხილოთ ეს საკითხი ქართული ლიტერატურის უძველესი ძეგლის, „წამებაი წმიდისა შუშანიკისი“-ს მაგალითზე.
ტექსტი, რომელიც ქვემოთ არის წარმოდგენილი, გახლავთ „შუშანიკის წამების“ ელექტრონული ვერსია – „სუფთა“ ტექსტი ყოველგვარი დამუშავების გარეშე:

იგივე ტექსტი, დედნის მიხედვით სტრუქტურირებული, ამგვარად გამოიყურება TITUS -ში:
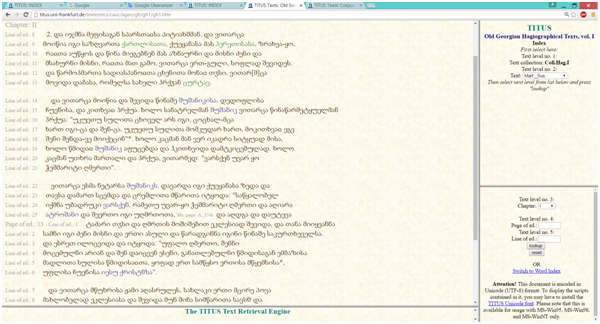
ამ ორ ტექსტს შორის სხვაობა იმაში მდგომარეობს, რომ ეს უკანასკნელი პირველად მოტანილი ტექსტის სტრუქტურირებულ ვერსიას წარმოადგენს: მასში ზუსტად არის მითითებული ძეგლის შიდა სტრუქტურა (სათაური, თავი პირველი, თავი მეორე და ა.შ.), ელექტრონულ ტექსტში სტრიქონებისა და გვერდების განლაგება ზუსტად ემთხვევა საყრდენ წყაროში ტექსტის განფენას (ელექტრონული ვერსია შექმნილია ძველი ქართული აგიოგრაფიული ლიტერატურის ძეგლების ბაზაზე, 1963 წ.). გარდა ამისა, ტექსტში დამატებით არის მარკირებული არსებითი სახელის სპეციფიკური ჯგუფები – ტოპონიმები, ანთროპონიმები და ჰიდრონიმები, რისთვისაც ელექტრონულ ტექსტში გამოყენებულია ტექსტის მარკირების საგანგებო ნიშნულები (Extensible Markup). ტექსტი დამუშავებულია ტექსტური მარკირების ყველაზე გავრცელებული ენის XML (Extensible Markup Language) ფორმატში:
2. მეტამონაცემი
კორპუსის მეორე უმნიშვნელოვანეს კომპონენტს წარმოადგენს მეტამონაცემი – ანუ მონაცემი ენობრივი მონაცემის შესახებ. მეტამონაცემი შეიცავს მეორად, განმავრცობელ ინფორმაციას პირველადი ენობრივი მონაცემის შესახებ, როგორიცაა მაგ.:
• მონაცემი პირველადი მონაცემის (მაგ., წარწერის, ხელნაწერის, ნაბეჭდი წიგნის) შექმნის ადგილის შესახებ;
• მონაცემის (ანუ პირველადი მონაცემის) ტექსტის ავტორის ვინაობის შესახებ;
• მონაცემი პირველად მონაცემთან დაკავშირებული რელევანტური თარიღების (შექმნის, გადაწერის) შესახებ.
და ასე შემდეგ.
მეტამონაცემი შესაძლოა თან ერთვოდეს პირველად მონაცემს – ტექსტს (იხ.TITUS) – ან განთავსდეს სპეციალური ფორმატის (header) დამოუკიდებელ ბაზაში:
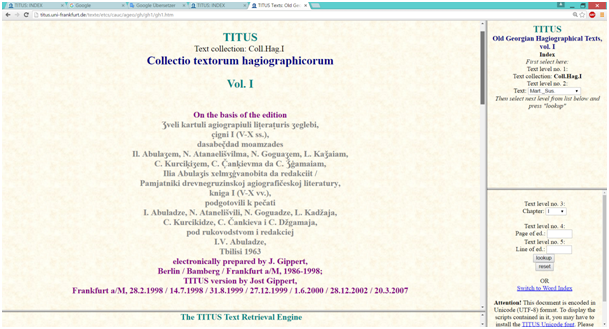
კორპუსების შექმნის ადრეულ პერიოდში, გასული საუკუნის 80-იან წლებში, როდესაც ჯერ კიდევ არ იყო დამუშავებული მეტაინფორმაციებისათვის საგანგებო სტრუქტურული დანართის პრინციპი და კრიტერიუმები, მეტამონაცემი თავად ჰქონდა დართული ტექსტს ერთგვარი ქუდის სახით, როგორც მაგ., TITUS -ის ბაზაში ჩართული გრაცის ხანმეტი ლექციონარის შემთხვევაში გვაქვს:

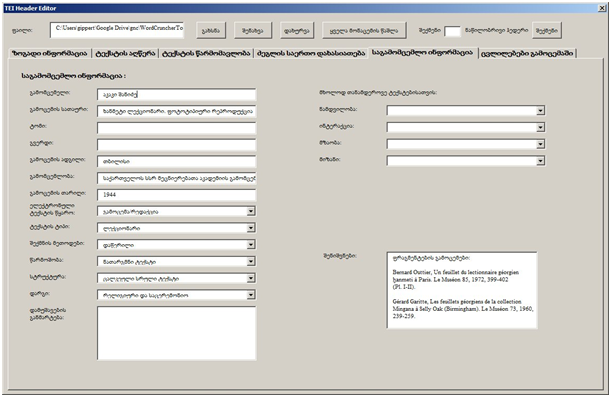
როგორც აქ მოტანილი ფრაგმენტიდან ჩანს, TITUS-ის ეს ტექსტი ეყრდნობა ნაშრომს, რომელიც 1944 წელს გამოსცა აკაკი შანიძემ ძველი ქართული ენის ძეგლების პირველ ტომში და რომელიც ხანმეტი ლექციონარის ფოტოტიპურ რეპროდუქციას წარმოადგენს.
ჰედერში მოცემულია აგრეთვე ინფორმაცია ელექტრონული ვერსიის შემქმნელთა (ამ კონკრეტულ შემთხვევაში ი. გიპერტის, ვ. იმნაიშვილის და ზ. სარჯველაძის) შესახებ. აქვეა მოცემული ინფორმაცია იმის შესახებ, თუ სად ინახება დედანი – ხელნაწერის ძირითადი ნაწილი ინახება გრაცის უნივერსიტეტის ბიბლიოთეკის ხელნაწერთა განყოფილებაში, ხელნაწერის პირველი გვერდი კი პარიზის ქართული ხელნაწერების ფონდშია დაცული და აღწერილია და გამოცემული ბერნარდ უტიეს მიერ 1972 წელს.
დღესდღეობით შემუშავებულია მეტაინფორმაციის საგანგებო სტრუქტურის – Header-ის სახით, რომელიც Header-ის აგების საერთაშორისო კონსორციუმის TEI (The Text Encoding Initiative) მიერ შემუშავებულ სტანდარტს ეყრდნობა. აღნიშნული სტანდარტი ემსახურება დიგიტალური ტექსტების საერთაშორისო მიმოქცევაში ჩართვას და აადვილებს რესურსების გამოყენებას საერთაშორისო სამეცნიერო სივრცის ფარგლებში.
The Text Encoding Initiative (TEI) is a consortium which collectively develops and maintains a standard for the representation of texts in digital form. Its chief deliverable is a set of Guidelines which specify encoding methods for machine-readable texts, chiefly in the humanities, social sciences and linguistics. Since 1994, the TEI Guidelines have been widely used by libraries, museums, publishers, and individual scholars to present texts for online research, teaching, and preservation. In addition to the Guidelines themselves, the Consortium provides a variety of resources and training events for learning TEI, information on projects using the TEI, a bibliography of TEI-related publications, and software developed for or adapted to the TEI.
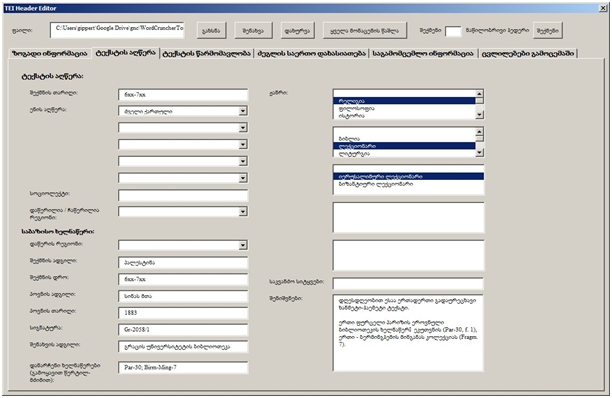
ზემოთ მოყვანილი გრაცის ხანმეტი ლექციონარის ტექსტის Header-ი ქართული ენის ეროვნულ კორპუსში ამგვარად გამოიყურება:
1
3. კორპუსმენეჯერი
კორპუსის ერთ-ერთ ძირითად შემადგენელ კომპონენტს წარმოადგენს კორპუსის მართვის მენეჯერი. კორპუსმენეჯერი უზრუნველყოფს ძიების პროცესს, რომელიც საშუალებას იძლევა ძიება განვახორციელოთ ერთი ან რამდენიმე პარამეტრის მიხედვით.
მაგალითად:
ა) მორფოლოგიური ნიშნის მიხედვით:
მომიძებნე ყველა, მოთხრობით ბრუნვაში მდგარი არსებითი სახელი;
ბ) ჰედერში მოცემული მეტამონაცემების მიხედვით:
მომიძებნე ყველა რესურსი, რომლის ავტორიც არის ილია ჭავჭავაძე;
ან
გ) ერთდროულად, ორივე სახის პარამეტრის მიხედვით:
მომიძებნე ყველა, მოთხრობით ბრუნვაში მდგარი სახელი იმ ტექსტებში, რომელიც ილია ჭავჭავაძის მიერაა შექმნილი.
კორპუს-საძიებო სისტემა, თავის მხრივ, შეიცავს კორპუსულ ძიებაზე მომართულ ექსპლორაციულ ალგორითმებს – საგანგებო ხელსაწყოს (ე.წ. tool), რომელიც უზრუნველყოფს კორპუსში ძიების პროცესს.
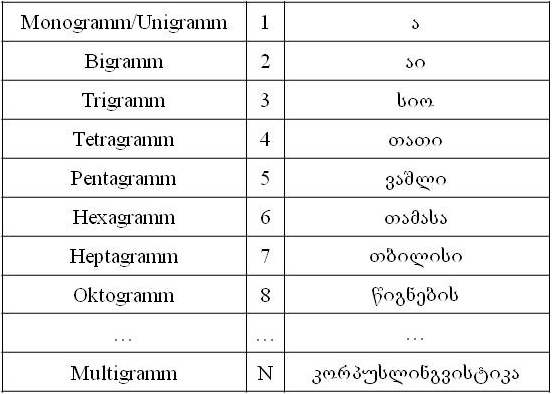
ძიების დროს ტექსტის დანაწევრება ხდება ფრაგმენტებად, რომელიც მეორე ეტაპზე ელემენტებად (n-gram) ჯგუფდება. ამგვარ დაჯგუფებას შესაძლოა საფუძვლად ედოს ასოების, მორფემების, ლექსემების მსგავსებები. n-gram-ის სახეებია: მონოგრამები, ბიგრამები, ტრიგრამები და ა.შ. გვხვდება მულტიგრამებიც შესამაბისად მაკონსტრუირებელი ნიშნის რაოდენობის მიხედვით.
n-gram-ი ფორმალურად ასე განისაზღვრება: თუ Σ სასრული ანბანია და n წარმოადგენს მთლიან დადებით რიცხვს, მაშინ n-gram-ი არის Σ ანბანისაგან შემდგარი ერთი w სიტყვა n სიგრძით, ანუ w=(w1,…,wn) ∈ Σn.
იხ. მაგალითი ქართულისათვის:
კორპუსული ძიება წარმოადგენს n-gram–ზე დაფუძნებულ მიზანმიმართულ ძიებას კორპუსში, რომლის ეფექტურობა მიემართება კორპუსის ინჟინერიის პრერეკვიზიტებს ანუ წინასწარ დადგენილ პირობებს.