ენათა თანამედროვე დოკუმენტირება არსებითად განსხვავდება ენის დესკრიფციისაგან, ვინაიდან იგი მიზნად ისახავს არა მხოლოდ ენის, როგორც ნიშანთა სისტემის კვლევას და აღწერას, არამედ კაცობრიობის სულიერი მემკვიდრეობის დოკუმენტირებასაც, კერძოდ:
- კულტურული მემკვიდრეობის შენახვას და გადაცემას ამ ენის მატარებელი სოციუმის მომდევნო თაობებისათვის;
- ყოვლისმომცველი და სრულფასოვანი ემპირიული მასალის შეკრებას ემპირიული კვლევებისათვის;
- მოპოვებული მასალების ინტერდისციპლინული კვლევებისათვის გამოყენების შესაძლებლობის შექმნას;
- საფრთხეში მყოფი ენის გადარჩენის ხელშეწყობას.
დიგიტალური დოკუმენტირება და არქივირება, დოკულინგვისტიკის მიხედვით, ეტაპობრივად ხორციელდება:
I. საველე ექსპედიციის (fieldwork) კონცეპტუალიზაცია და პრაქტიკული გამხორციელება
სამეცნიერო ექსპედიციის ჩატარებამდე აუცილებელია ექსპედიციის კონცეპტუალური დაგეგმვა:
- ექსპედიციის გეგმა-გრაფიკის შემუშავება;
- ექსპედიციის პრაქტიკული განხორციელების ოპტიმირება ისეთი რისკ-ფაქტორების გათვალისწინებით, როგორებიცაა, მაგალითად, სახელმწიფო-პოლიტიკური, კლიმატური, რელიგიური ფაქტორები, საომარი მოქმედების ზონა, საზოგადოების სოციალური სტრუქტურა და ა. შ.;
მასალების საველე პირობებში მოპოვების პროცესში აუცილებელია დოკულინგვისტიკის ძირითადი პრინციპების გათვალისწინება, კერძოდ:
- მასალის მოპოვება ენობრივი კომპეტენციის განსხვავებული საფეხურების შესაბამისად;
- ენის/დიალექტის გამოყენების სფეროების დადგენა ბილინგვალიზმის პირობებში;
- კოდების ცვლისა და ენის/დიალექტის საფრთხეში ყოფნის ინდიკატორების დადგენა;
- ასაკობრივი ცენზისა და გენდერული ბალანსის დაცვა;
- თემატურად მრავალფეროვანი მასალის მოპოვება.
თემატური მასალების მოპოვების დროს აუცილებელია ინტერვიუების ბუნებრივ პირობებში ჩაწერა. მაგ., ვაზის კულტურის შესახებ ინტერვიუ სასურველია ყურძნის მოსავლის აღების დროს დაიგეგმოს, რელიგიური და რიტუალური თემების შესახებ ინტერვიუები პროცედურულ ან სადღესასწაულო რიტუალების დროს უნდა ჩაიწეროს.
დოკუმენტაციის დროს გამოიყენება როგორც ობსერვაციული მეთოდი (სიტუაციებზე და მოვლენებზე დაკვირვების მეთოდი), ისე ელიციტაციური მეთოდი (ინფორმანტების მიზნობრივი გამოკითხვის მეთოდი).
მასალის გადაღების პროცესში გასათვალისწინებელია ტექნიკური პარამეტრების დაცვა:
- გადაღების ობიექტის განსაზღვრა,
- კადრების მონაცვლეობის აუცილებლობის განსაზღვრა,
- გამოსახულების ოპტიმირება,
- გადაღების ხედის ცვლა.
დოკუმენტირების პროცესში გადაღებული ვიდეომასალა არ არის მხატვრული ან დოკუმენტური ფილმისათვის განკუთვნილი, ამიტომ სასურველია კადრების ცვლილების სიხშირე მინიმუმამდე შევამციროთ.
II. მოპოვებული მასალის ლაბორატორიული დამუშავება
საველე ექსპედიციაში მოპოვებული მასალები დოკუმენტირების შემდგომ ეტაპზე ლაბორატორიულად მუშავდება.
უპირველეს ყოვლისა, მიმდინარეობს მოპოვებული მასალების აღრიცხვა საერთაშორისო სტანდარტის TEI (Text Encoding Initiative) მიხედვით. საერთაშორისო ორგანიზაცია TEI 1987 წელს დაარსდა და 2000 წლიდან ფუნქციონირებს TEI-კონსორციუმის სახელით. ორგანიზაციის და შემდგომ კონსორციუმის მიზანს წარმოადგენდა დოკუმენტთა (რესურსთა) საერთაშორისო სტანდარტის შექმნა ელექტრონული ტექსტების ურთიერთგაცვლის მიზნით. კონსორციუმის მიერ შემუშავებულ TEI-ფორმატს, რომელიც შეიცავს ინფორმაციებს ტექსტის მახასიათებელი ნიშნების გათვალისწინებით: ტექსტის სათაური, ავტორი, წარმოშობა, სტრუქტურა და ა.შ. TEI-ფორმატისათვის იყენებენ მეტაენას, რომელიც მაგ., DTD ან XML ფორმატში არის წარმოდგენილი.
მაგ.:

იმისათვის, რომ მოპოვებული მასალები ინტერდისციპლინული კვლევის რესურსად გარდავქმნათ, საჭიროა მათი საგანგებო დამუშავება ტექნიკური თვალსაზრისით. კერძოდ:
ა) მოპოვებული მასალები უნდა გადავიყვანოთ AVI (Audio Video Interleave) ფორმატში;
ბ) AVI ფორმატში გადაყვანილ ფაილები თემების მიხედვით დავჭრათ ცალკეულ ფაილებად და დავახარისხოთ (Making Session);
გ) თითოეული ფაილისათვის მოვამზადოთ მეტამონაცემები საერთაშორისო სტანდარტის საგანგებო ფორმატის IMDI [ISLE (International Standard for Language Engineering ) Meta Data Initiative] მიხედვით.
ELAN (Electronical Anotation) – მულტიმედიალური ანოტირების პროფესიული ინსტრუმენტი
მეტამონაცემების საერთაშორისო სტანდარტის ეს ფორმატი (IMDI) შეიცავს შემდეგი სახის მეტამონაცემებს:
- მასალის ჩაწერის დრო და ადგილი;
- მასალის შინაარსის თემატური აღწერა;
- მონაცემები მთქმელის შესახებ (ასაკი, განათლება, მიგრაციული ფონი);
- კონვერსაციის ტიპი (მონოლოგი, დიალოგი, სიტუაციური კადრები, კადრები ენობრივი რესურსების გარეშე).
ლაბორატორიული დამუშავების შემდგომ ეტაპზე მიმდინარეობს ჩაწერილი მასალის გადმოწერა (ტრანსკრიბირება) და ლინგვისტური დამუშავება, კერძოდ:
- მასალების ტრანსკრიბირება კოდირების საერთაშორისო კონსორციუმის Unicode -ის სტანდარტების შესაბამისად;
- ტრანსკრიბირებული მასალის გადატანა მონაცემთა მართვის, ტექსტის გარჩევისა და ანალიზის მულტიმედიურ ფორმატში Toolbox (Data management, parsing and text analysis);
- ვიდეო, აუდიო და მულტიმედიურად ანოტირებული ფორმატების სინქრონიზაცია EAF (ELAN Annotation Format) ფაილში.
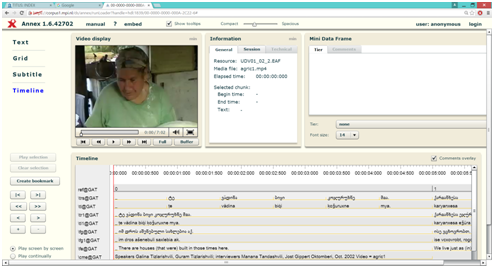
EAF – საარქივო მულტიმედიალურ ფორმატი
III. დამუშავებული რესურსების არქივირება და შემდგომი დაცვა
ლაბორატორიულად დამუშავებული მასალების დიგიტალურ რესურსად გარდაქმნა არ ნიშნავს დიგიტალური დოკუმენტირების დასრულებას. საჭიროა მათი განთავსება დიგიტალურ არქივში დიგიტალური რესურსების შემდგომი შენახვის, მოვლისა და დაცვის ტექნიკური უზრუნველყოფის მიზნით. დიგიტალურად დამუშავებული რესურსების არქივირება დიგიტალური დოკუმენტირების ბოლო ეტაპია. თუ ასეთი არქივი არ არსებობს, საჭიროა დიგიტალური არქივის შექმნა.
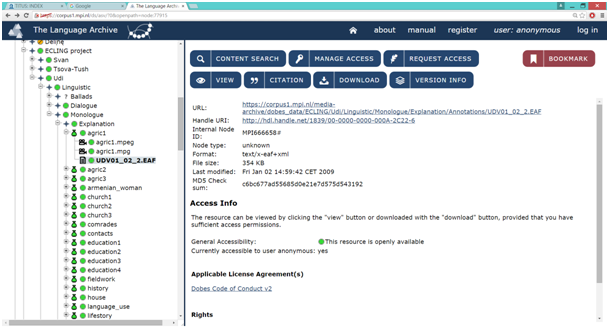
რესურსების შენახვის თანამედროვე სტანდარტი – საარქივო ვიდეოების სეგმენტირება, კატალოგიზირება და არქივირება
დიგიტალური არქივის შექმნა აუცილებელი და სავალდებულოა მასალის დაცვის მიზნით, ვინაიდან:
ა) მხოლოდ არქივის შექმნა საკმარისი არ არის; საჭიროა არქივის დუბლირება/მულტიპლიცირება სარკისებური სერვერების სახით;
ბ) აუცილებელია აღნიშნული სერვერ(ებ)ის ავტომატური სათადარიგო ასლით (Backup) უზრუნველყოფა.
არქივირების შემდეგი ეტაპია ჩამოთვლილი კომპონენტების შედეგად მიღებული ინტერდისციპლინური რესურსების ღია ინტერნეტსივრცეში განთავსება, ანუ რესურსების შეუფერხებელი მოხმარებისა (OR – Open-Ressource) და გაცვლის (RE – Ressource Exchange) უზრუნველყოფა.
აქ ჩამოთვლილი სამივე ეტაპის სრულფასოვანი განხორციელება – 1. საველე ექსპედიციის (fieldwork) კონცეპტუალიზაცია და პრაქტიკული გამხორციელება, 2. მოპოვებული მასალის ლაბორატორიული დამუშავება და 3. ლაბორატორიულად დამუშავებული რესურსების არქივირება და შემდგომი დაცვა – დოკულინგვისტიკის ძირითად პრინციპს წარმოადგენს.
რესურსების მოპოვების, დამუშავებისა და დაცვის საერთაშორისო გამოცდილება
თანამედროვე მეცნიერება ერთგვარი სინერგიით ხასიათდება. საერთაშორისო სამეცნიერო საზოგადოება კვლევითი რესურსების ინტერდისციპლინურობისა და ინტეგრაციისაკენ მიისწრაფვის. ამის დასტურია, მაგ., სამეცნიერო კონსორციუმის CLARIN (Common Language Resources and Technology Infrastructure) შექმნა.
ენობრივი რესურსებისა და ტექნოლოგიური ინფრასტრუქტურის განვითარების საერთოევროპული გაერთიანება – კონსორციუმი CLARIN აერთიანებს სხვადასხვა სამეცნიერო დარგის მეცნიერებს, რომლებიც კონსორციუმის პლატფორმას რესურსების გაცვლის, ინოვაციური ტექნოლოგიების განვითარების-სტანდარტიზაციის და დიგიტალურ მონაცემთა მდგრადი შენახვის პრობლემებზე მუშაობისათვის იყენებენ.
CLARIN-ში გაერთიანებული არიან ევროპის შემდეგი ქვეყნები: გერმანია, ბულგარეთი, დანია, ესტონეთი, საბერძნეთი, ლიტვა, ჰოლანდია, ნორვეგია, ავსტრია, პოლონეთი, პორტუგალია, შვედეთი, ჩეხეთი, ბრიტანეთი.თითოეულ წევრ ქვეყანას გააჩნია ეროვნული CLARIN-ორგანიზაცია, მაგ., გერმანიაში შექმნილია CLARIN-DE, რომელშიც შემდეგი კვლევითი ცენტრები და ინსტიტუციები არიან გაერთიანებული:
- University of Tübingen – Annotated Corpora (treebanks), lexical data, data from experiments, linguistic knowledge components and web services
- University of Leipzig (ASV) – Lexical data, web services and special reference-corpora, public data
- BBAW Berlin – German language, lexicons, diachrone corpora (before 1900), digital editions
- University of Stuttgart (IMS) – Computational linguistics software, for example: corpora and tools, parameter-based tools and web services
- IDS Mannheim – German language, big corpora of German (after 1900), language of minorities (dialects)
- LMU Munich (BAS) – German language and multimodal data, phonetical tools and services
- MPI Nijmegen – Language of minorities, endangered languages, multimedia and multimodal data, data from experiments, sign language
- University of Hamburg – Multilingual spoken corpora, transcription tools, sign language
- University of Saarland – Multilingual corpora and corpus tools
რესურსები:
ISLE – http://www.mpi.nl/ISLE/
Toolbox – http://www-01.sil.org/computing/toolbox/
TEI – http://www.tei-c.org/index.xml