დღესდღეობით ანოტაციის ყველაზე გავრცელებული ფორმა არის POS-ანოტაცია (Part Of Speech Annotation) ანუ სიტყვაფორმის დახასიათება მეტყველების ნაწილის მიხედვით. სამეცნიერო ნაშრომებში გამოყენებული ტექსტის ლინგვისტური ანოტაცია, კორპუსული ანოტაციისაგან განსხვავებით, მანუალურად იქმნება და შრომატევადია.
იხ. მანუალური ლინგვისტური ანოტაციის მაგალითი:
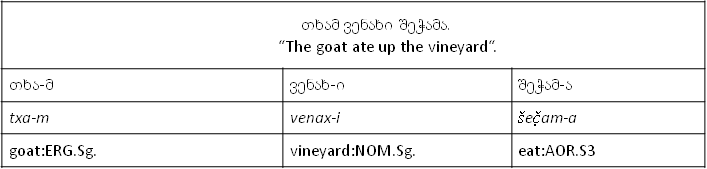
კორპუსში ლინგვისტური მონაცემების POS-ანოტაციის შემოტანამ ამ მონაცემების ინტერნაციონალურ გამოყენებას ჩაუყარა საფუძველი და შესაძლებელი გახადა სხვადასხვა ენათა ლინგვისტური მასალების ტიპოლოგიური კვლევებისათვის მოძიება.
ანოტაციის განსახორციელებლად გამოიყენება ნოტაციის კონვენციური წესები, რომელიც სამეცნიერო ნაშრომებში აპრობირებული მარკერების ნაკრებს წარმოადგენს და მონაცემთა საგანგებო ბანკის სახით (feature) დაერთვის ნებისმიერ კორპუსს. ანოტაციის მარკერები, როგორც წესი, ინგლისურენოვანი ცნებების პირობითად შემოკლებული ვარიანტებია:
NOM < nominative
Act < active
PL < plural
და ა.შ.
ლინგვისტური ანოტაცია ენობრივი მონაცემების ლინგვისტური დამუშავების შედეგად ხორციელდება და მისი რამდენიმე სახე არსებობს. მანუალური ანოტაცია კი ეტაპობრივად მიმდინარეობს და რამდენიმე პროცედურისაგან შედგება:
1. ტრანსკრიბირება – ენობრივი მონაცემის „გადმოწერა“ წინასწარ შეთანხმებული წესების მიხედვით ან ტრანსკრიფციის საერთაშორისო წესების დაცვით;
2. სეგმენტირება – სიტყვაფორმის დანაწევრება ლინგვისტური ინფორმაციის მატარებელ (უმცირეს) ფუნქციურ ელემენტებად;
3. კვალიფიცირება – სეგმენტაციის შედეგად გამოყოფილი ელემენტების ფუნქციურ-გრამატიკული განსაზღვრა.
განვიხილოთ თითოეული ეტაპი ცალ-ცალკე.
ტრანსკრიბირება
ენობრივი მონაცემის ტრანსკრიბირება ლინგვისტური ანოტაციის აუცილებელ კომპონენტს წარმოადგენს. საკუთარი დამწერლობის მქონე ენებისათვის იგი ანოტაციის მეორე ველში განთავსდება, დამწერლობის არმქონე ენების შემთხვევაში კი ანოტაციის პირველსავე ველში იქნება მოცემული. ამასთან, უნდა გავითვალისწინოთ, რომ ტრანსკრიბირების რამდენიმე შესაძლებლობა არსებობს. ზემოთ მოყვანილი მაგალითი შეიძლება ტრანსკრიბირების სამი სხვადასხვა სახით ჩავწეროთ:
GE: თხამ ვენახი შეჭამა
ENG: tkham venakhi shetchama
LT: txam venaxi šeč̣ama
IPA: t’xam venaxi ʃeʄ˞ama
როგორც ვხედავთ, ერთი და იგივე წინადადება ტრანსკიფციის სხვადასხვა ველში განსხვავებული სახით არის მოცემული:
• ENG-ის შემთხვევაში ქართული ფონემების ინგლისურად ნოტაციის წესია გამოყენებული (kh=ხ, sh=შ),
• LT–ში გამოიყენება ლინგვისტური ტრანსკრიფციის ნიშნები,
• IPA (Intenational Phonetic Alphabet) კი იყენებს საერთაშორისო ფონეტიკური ანბანის აღნიშვნებს.
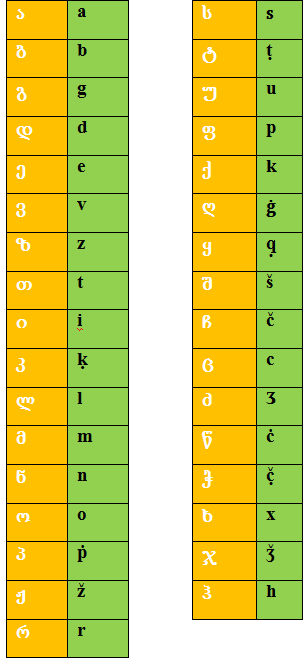
ტრანსკრიბირების დროს სასურველია გამოვიყენოთ ლინგვისტური ტრანსკრიფცია, რომელიც ცხრილის სახით ქვემოთ არის მოცემული.
სეგმენტირება
ანოტირების შემდეგ ეტაპს წარმოადგენს სეგმენტირება. სეგმენტირების დროს ძირითადად ისეთი პრობლემები იჩენს თავს, როგორიცაა ფუძის განსაზღვრის საკითხი.
მაგალითი სახელის მორფოლოგიიდან:
შდრ.:
ქუდ-ს vs. ქუდიან-ს / ქუდ=იან-ს
შდრ.:
ლამაზ-მა vs. ულამაზეს-მა / უ=ლამაზ=ეს-მა
როგორც პირველ, ისე მეორე შემთხვევაში ჩვენ ვამჯობინებთ სეგმენტირების მეორე ვერსიას და უპირატესობას ვანიჭებთ ფორმებს: ქუდ=იან–ს და უ=ლამაზ=ეს–მა.
მაგალითი ზმნური მორფოლოგიიდან:
გააკეთებს vs. გააკეთებინებს
შდრ.: გა-ა-კეთ-ებ-ს vs. გა-ა-კეთ-ებ-ინ-ებ-ს / გა-ა-კეთ=ებ-ინ-ებ-ს
–ებ თემის ნიშანს გა-ა-კეთ=ებ-ინ-ებ-ს ფორმაში აღარ აქვს ის ფუნქცია, რომელიც გა-ა-კეთ-ებ-ს ფორმაში აქვს. მას ჩვენ ზმნის კაუზატიური ფორმის ფუძის ნაწილად განვიხილავთ და ამიტომ ტოლობის ნიშანს ვსვამთ ზმნურ ძირსა (-კეთ-) და მის მომდევნო –ებ-ს შორის.
კვალიფიცირება
სიტყვაფორმის სეგმენტირების შემდეგ ხორციელდება გამოყოფილი ელემენტების კვალიფიცირება: ერთმანეთისაგან უნდა გაიმიჯნოს მორფოლოგიური და ლექსიკური ელემენტები, ანუ უნდა განხორციელდეს ლემატიზაცია.
ლემატიზაციის შემდეგ ეტაპს წარმოადგენს ე.წ. POS–ანოტაცია (Part-Of-Speech tagging). POS -ანოტაცია გულისხმობს პროცესს, რომლის დროსაც ყველა სიტყვაფორმას ენიჭება მეტყველების ნაწილის აღმნიშვნელი თეგი.
მაგ.: არსებითი სახელი აღინიშნება თეგით N, ზმნა –V, ზმნიზედა – Adv და ა.შ.
ქართული ენის POS-ანოტაციისათვის საჭირო თეგები წარმოდგენილია ქვემოთ მოცემულ ცხრილში. თეგების ცხრილი ითვალისწინებს როგორც GNC-ს (ქართული ენის ეროვნული კორპუსი) თეგებს, ისე მაია ლომიასა და რუსუდან გერსამიას თეორიულ ნაშრომს „ხაზთაშორისი მორფემული გლოსირება“ (2012).
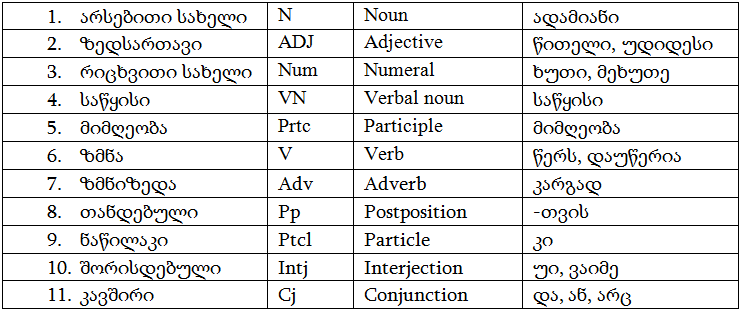
მეტყველების ნაწილების აღმნიშვნელი თეგები:
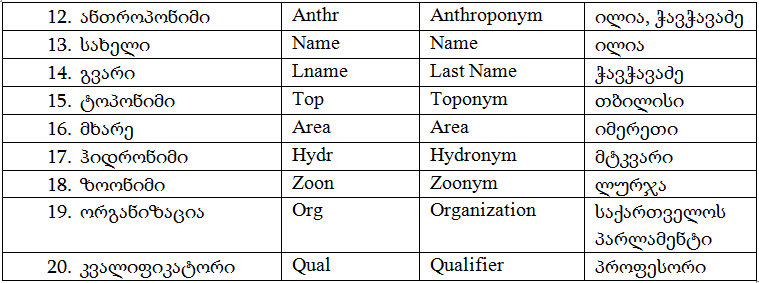
არსებითი სახელისათვის რელევანტური სემანტიკური თეგები:
არსებითი სახელისათვის რელევანტური მორფოლოგიური და მორფოსინტაქსური ელემენტების თეგები:
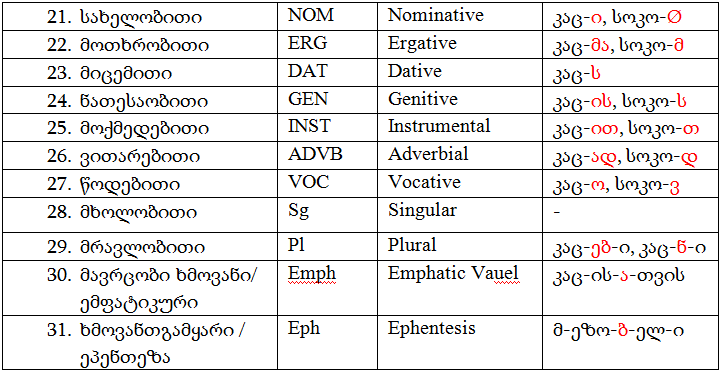
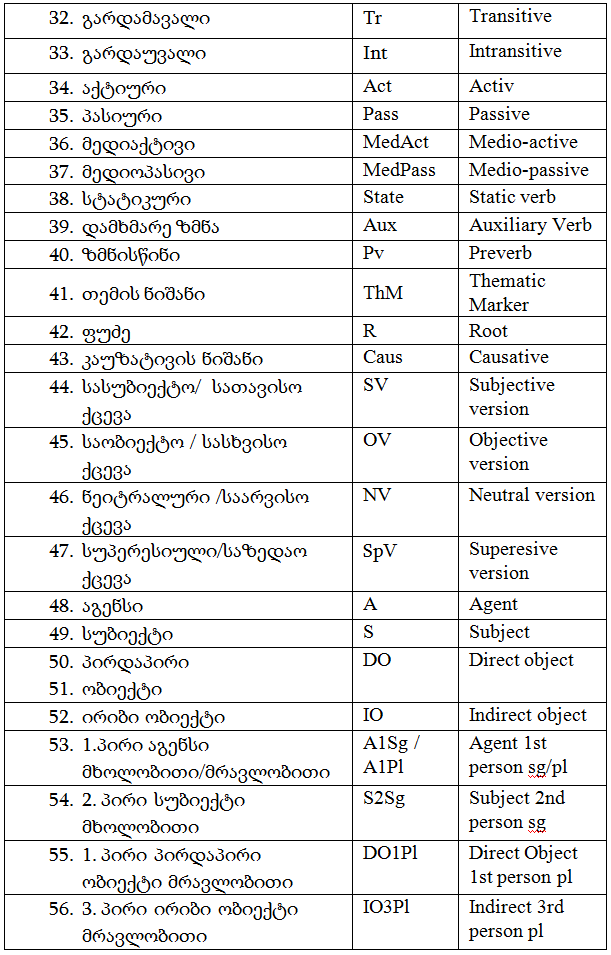
ზმნისათვის რელევანტური მორფემებისა და სემანტიკურ-სტრუქტურული ნიშნების აღმნიშვნელი თეგები:
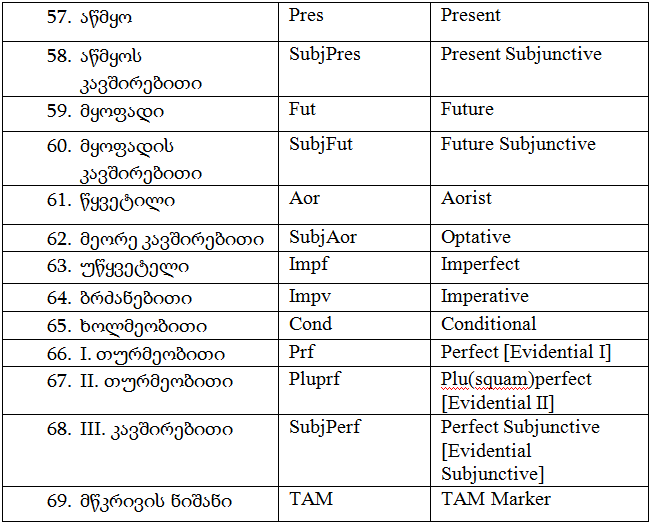
მწკრივების აღმნიშვნელი თეგები:
რიცხვითი სახელისათვის რელევანტურ ნიშანთა აღმიშვნელი თეგები:

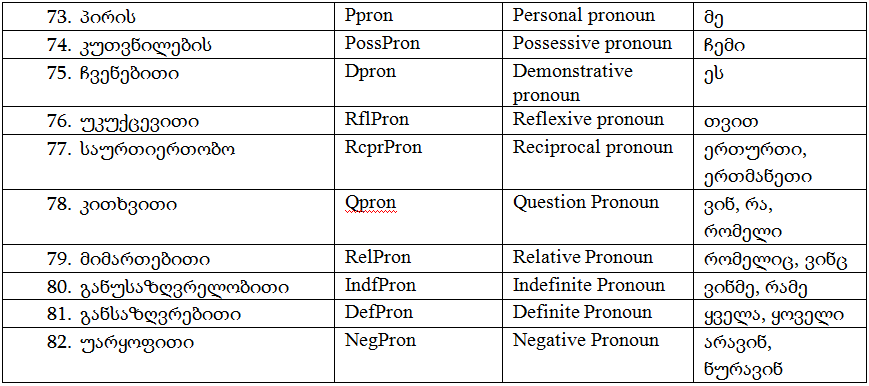
ნაცვალსახელთა ჯგუფების აღმიშვნელი თეგები:
ნაწილაკების ფუნქციურ-სემანტიკური დაჯგუფებისათვის რელევანტური თეგები:
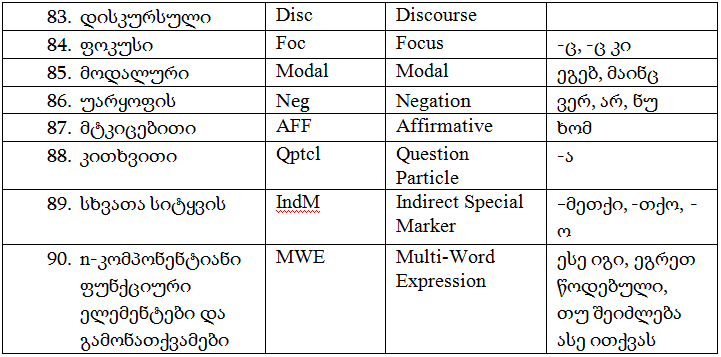
იმისდა განურჩევლად, თუ რა სახის ანოტაციას ვიყენებთ – მანუალურს, ავტომატურს თუ სემი-ავტომატურს – აუცილებელია შევთანხმდეთ ერთ საკითხზე: რა ტიპის ანოტირება გვსურს ლინგვისტური ანოტაციის დროს: დესკრიფციული თუ ანალიტიკური. ეს არსებითი საკითხია, რომელსაც საგანგებოდ განვიხილავთ ქვემოთ ანოტაციის ტიპებში.